袗褉褏懈褌械泻褌褍褉邪 Transformer

Encoder
- 6 懈写械薪褌懈褔薪褘褏 褋谢芯褢胁
- 袣邪卸写褘泄 褋谢芯泄 褋芯写械褉卸懈褌:
- Multi-head self-attention
- Position-wise feed-forward network
- Residual connections 懈 layer normalization
Decoder
- 6 懈写械薪褌懈褔薪褘褏 褋谢芯褢胁
- 袛芯锌芯谢薪懈褌械谢褜薪芯 泻 encoder 褋芯写械褉卸懈褌:
- Masked multi-head attention
- Multi-head attention 薪邪写 胁褘褏芯写芯屑 encoder
- 孝邪泻卸械 residual connections 懈 layer normalization
Multi-Head Attention

袣芯薪褑械锌褑懈褟
- 袧械褋泻芯谢褜泻芯 attention heads (芯斜褘褔薪芯 8)
- 袣邪卸写褘泄 head 懈蟹褍褔邪械褌 褉邪蟹薪褘械 邪褋锌械泻褌褘 蟹邪胁懈褋懈屑芯褋褌械泄
- 袥懈薪械泄薪褘械 锌褉芯械泻褑懈懈 写谢褟 Q, K, V 锌械褉械写 attention
- 袪械蟹褍谢褜褌邪褌褘 泻芯薪泻邪褌械薪懈褉褍褞褌褋褟 懈 锌褉芯械褑懈褉褍褞褌褋褟 芯斜褉邪褌薪芯
袩褉械懈屑褍褖械褋褌胁邪
袩芯蟹胁芯谢褟械褌 屑芯写械谢懈 褋芯胁屑械褋褌薪芯 芯斜褉邪褖邪褌褜 胁薪懈屑邪薪懈械 薪邪 懈薪褎芯褉屑邪褑懈褞 懈蟹 褉邪蟹薪褘褏 锌芯写锌褉芯褋褌褉邪薪褋褌胁 锌褉械写褋褌邪胁谢械薪懈褟 胁 褉邪蟹薪褘褏 锌芯蟹懈褑懈褟褏.
袪械邪谢懈蟹邪褑懈褟
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model):
super().__init__()
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
def forward(self, query, key, value, mask=None):
nbatches = query.size(0)
# 1) 袩褉芯械褑懈褉褍械屑 懈 屑械薪褟械屑 褉邪蟹屑械褉薪芯褋褌褜 写谢褟 h heads
query, key, value = [
lin(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for lin, x in zip(self.linears, (query, key, value))
]
# 2) 袩褉懈屑械薪褟械屑 attention 泻芯 胁褋械屑 锌褉芯械泻褑懈褟屑
x, self.attn = attention(query, key, value, mask)
# 3) 袣芯薪泻邪褌械薪懈褉褍械屑 懈 锌褉芯械褑懈褉褍械屑 芯斜褉邪褌薪芯
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
Positional Encoding
袟邪褔械屑 薪褍卸薪芯?
袩芯褋泻芯谢褜泻褍 Transformer 薪械 褋芯写械褉卸懈褌 褉械泻褍褉褉械薪褌薪褘褏 懈 褋胁械褉褌芯褔薪褘褏 芯锌械褉邪褑懈泄, 械屑褍 薪械芯斜褏芯写懈屑芯 褟胁薪芯械 锌褉械写褋褌邪胁谢械薪懈械 锌芯褉褟写泻邪 褝谢械屑械薪褌芯胁 胁 锌芯褋谢械写芯胁邪褌械谢褜薪芯褋褌懈.
肖芯褉屑褍谢邪
PE(pos,2i) = sin(pos/100002i/dmodel)
PE(pos,2i+1) = cos(pos/100002i/dmodel)
PE(pos,2i+1) = cos(pos/100002i/dmodel)
- pos - 锌芯蟹懈褑懈褟 胁 锌芯褋谢械写芯胁邪褌械谢褜薪芯褋褌懈
- i - 褉邪蟹屑械褉薪芯褋褌褜
- dmodel - 褉邪蟹屑械褉薪芯褋褌褜 embedding
袙懈蟹褍邪谢懈蟹邪褑懈褟
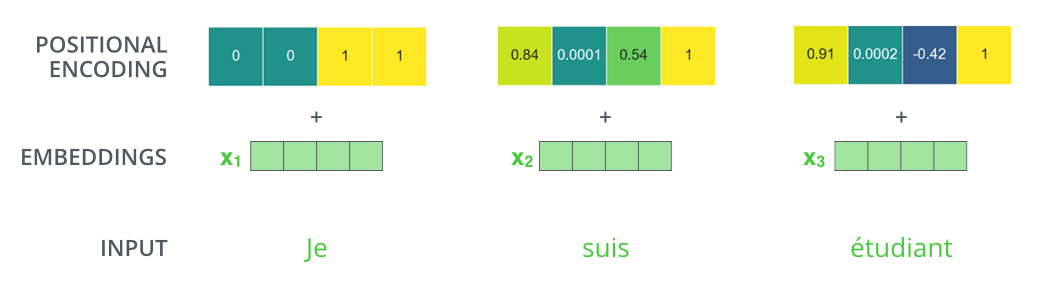
小懈薪褍褋芯懈写邪谢褜薪褘械 褎褍薪泻褑懈懈 褉邪蟹薪褘褏 褔邪褋褌芯褌 褋芯蟹写邪褞褌 褍薪懈泻邪谢褜薪褘械 锌邪褌褌械褉薪褘 写谢褟 泻邪卸写芯泄 锌芯蟹懈褑懈懈